Writing from left to right, one word after another—is that a necessity of intelligence, or merely a human habit? If an intelligence could express itself out of order—setting down the beginning and the ending at the same time—would the world it sees still be the same one?
In the science-fiction novella Story of Your Life, an alien species known as the heptapods arrives on Earth. Linguist Louise Banks is recruited by the military to communicate with the visitors and find out why they have come. In the course of this exchange, Louise learns their written language, “Heptapod B”. Unlike human languages, it is not laid out linearly along a direction of writing; instead, it emerges as a whole, in circular form. Before a heptapod “writes”, it already knows the complete shape of everything it wants to express, and then draws the entire passage at once. Arrival, the film adapted from the novella, vividly depicts how Heptapod B is written:

As the communication deepens, Louise realizes that the heptapods’ language embodies the way they perceive the world: their physics is built on teleological principles (much like Fermat’s principle of least time, where light seems to “know in advance” the endpoint it will reach), and on that foundation they know the past, present, and future simultaneously. As Louise grows more fluent in Heptapod B, the structure of her own consciousness begins to change. Like the heptapods, she starts to experience time non-linearly; she begins to “remember” the future, including the entire life of her future daughter. “Story of Your Life” is both the title of the novella and the letter Louise writes to her daughter—a letter in which she recounts, in the second person, fragments of her yet-unborn daughter’s life: conception, birth, growing up, the small details of living, all the way to the final ending.
Ted Chiang’s novella contains two intriguing and important ideas: 1. Language is not merely a tool for communication—people voice their thoughts through language, but language in turn shapes the way they perceive the world. 2. The world is deterministic; the future is predictable, or rather “known in advance”. The so-called past, present, future, and free will are only how humans experience the world—perhaps even an illusion. Combined, the two form a bold conjecture: if humans were to abandon their linear, causal way of speaking and writing, reshaping language into a holistic form of expression, they could change the way they see and understand the world—and thereby perceive the past, present, and future all at once.
Let us turn our gaze from science fiction back to the real world, and to large language models. Since the debut of ChatGPT at the end of 2022, large language models (LLMs) have rapidly become the most important achievement in artificial intelligence, reshaping industry after industry while advancing at breakneck speed. Today, their capabilities have long surpassed what anyone initially imagined. Agents built around LLMs can serve as everyday personal assistants (OpenClaw) and complete complex, long-horizon programming tasks (Claude Code, Codex). LLM-based reasoning models have reached the frontier of mathematical research (in May 2026, OpenAI’s general reasoning model autonomously disproved the “unit distance conjecture” posed by mathematician Paul Erdős in 1946). The foundation beneath these skyscrapers consists of two core techniques: 1. sequence models based on the Transformer architecture; 2. training and inference based on next-token prediction. Transformer models use self-attention to learn how strongly elements at different positions of a sequence influence one another, while next-token prediction imitates the human writing process: given what has already been written (the context), write what comes next.
Next-token prediction is undeniably an efficient paradigm: it lets models learn from humanity’s vast corpus of text without any extra supervision signal, and it keeps training and inference consistent with each other. But one thing is often overlooked: next-token prediction is itself an extremely strong assumption—the word to be written now is determined by the part already written. Once the current word is decided, it merges with the history to determine the words of the future. This way of writing matches the human habit of causal inference, and the language models trained on it are today’s mainstream LLMs: autoregressive language models. In Story of Your Life, it is precisely this causal mode of thinking that confines humans to experiencing time linearly—past, present, and future in strict order, with the future unknowable. And this has been inherited wholesale by autoregressive modeling: through the causal mask, self-attention allows each token to see only the tokens that come before it, never the future.
Artificial intelligence models are not born with humanity’s millennia of accumulated feeling for the passage of time, nor with the tacit, linear mode of thinking built upon it. So for models striving toward ever-higher intelligence, is this writing paradigm—inherited from the inertia of human causal reasoning—a help, or a constraint?
To answer this question, we can look back at a model that already achieved superintelligence in a specific domain: AlphaGo-Zero, in the game of Go. Early versions of AlphaGo first learned by imitating human game records, then strengthened themselves through self-play. AlphaGo-Zero, by contrast, discarded the step of learning from human games entirely and evolved purely through self-play. In the end, AlphaGo-Zero surpassed the Go AIs trained on human games, and surpassed human players by an even wider margin. Its style of play broke free from the experience and established patterns humans had accumulated over centuries—and even ended up offering human players a new paradigm to learn from.
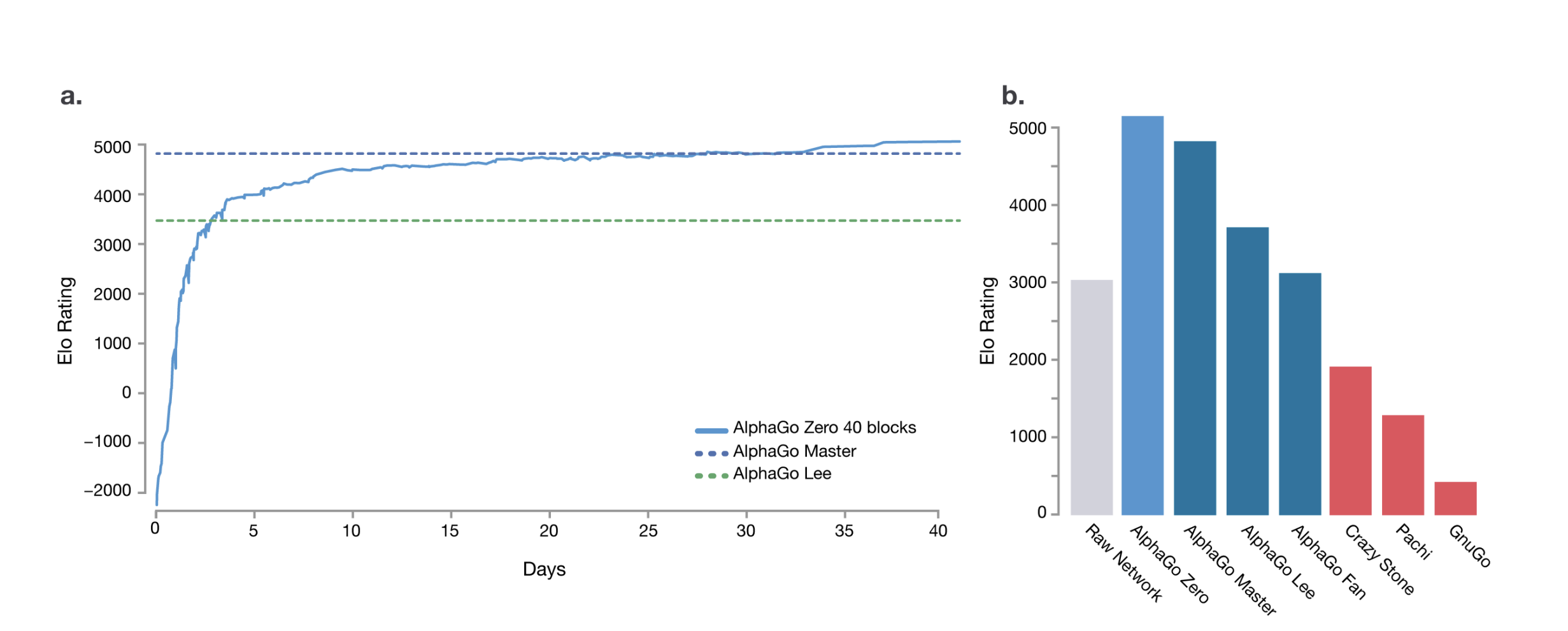
If Richard Sutton’s The Bitter Lesson[1] teaches us the importance of scaling for the evolution of AI, then the success of AlphaGo-Zero teaches us that human prior knowledge is not always reliable for that evolution.
Of course, AlphaGo-Zero cannot be transplanted directly onto language: Go has a clear win-or-lose signal, so the model can obtain supervision from self-play and abandon human data altogether, whereas language models must still learn from human text—there is no “completely discarding human experience” here. But the real point of the analogy is this: human priors are not necessarily the road to higher intelligence—and the left-to-right order of generation is precisely one of the priors we inject into our models almost without reflection. It comes from human writing habits and causal intuition, but it is not necessarily a requirement of intelligence itself.
It is undeniable that, building on “causal inference”, autoregressive language models can go on to learn the human way of “reasoning”, and reasoning models do indeed help humans solve very complex problems. But left-to-right reasoning also brings dilemmas of its own making: when facing tasks that require global planning (think of Sudoku), a sequence of local optima is often not the global optimum; and if an earlier step of reasoning is wrong, causal inference compounds the error—all of which forces the reasoning process into trial-and-error and backtracking. And so a fascinating possibility emerges: if a language model gave up the fixed, sequential generation paradigm, could it, like AlphaGo-Zero, reach ways of thinking and levels of intelligence beyond the human?
Compared with autoregressive models that predict the next token, diffusion language models offer a highly promising candidate answer for intelligence beyond the human—a way of generating language that happens to coincide with “Heptapod B”: a diffusion language model does not strictly enforce a left-to-right writing order; the entire passage emerges as a whole through “denoising”.
Concretely, during training, a diffusion language model adds noise to unlabeled text, with the training objective of recovering the original text from the noise. During inference, the text to be generated develops step by step out of noise into its final form. Throughout this process, the model need not follow a left-to-right writing order: the future (text that comes later) and the present (the middle) may well appear before the past (text that comes earlier). If we regard writing as a process of recovering “truth” from “chaos”, then the truth a diffusion language model recovers carries a kind of temporal equality and causal indifference—present, past, and future can emerge together, with no obligation to obey the strict linear order of past, present, future that autoregressive models must follow.
Some may object: words and language are merely carriers of knowledge and wisdom—when we learn from books and papers, what we learn is the information and ideas behind the symbols, regardless of which language we read or write. But “language shapes consciousness” is not merely a science-fiction fantasy. The weak version of the Sapir–Whorf hypothesis (that language influences thought) has considerable empirical support. For example, the Australian Aboriginal language Guugu Yimithirr uses no body-centered directional words like “left/right”, relying instead on absolute directions such as north, south, east, and west—and its speakers develop an unusually precise sense of orientation. Heidegger wrote in the Letter on Humanism that “language is the house of Being” (Die Sprache ist das Haus des Seins): language is the place where Being is cleared and revealed (aletheia, unconcealment). For Heidegger, the language we dwell in opens up a particular world and lets beings appear in a particular way. The “Heptapod B” of Story of Your Life opens up a world in which all times are co-present—future and present appearing together. This resonates with Heidegger’s account of logos as “gathering” (Versammlung): not a linear laying-out, but bringing a whole into the open at a single stroke. Our understanding of wisdom—indeed of the world itself—remains shallow: to this day, intelligence has no precise definition. Under these circumstances, we have good reason to take seriously the possibility that a non-linear, non-causal language could give rise to a cognition of the world that is different from—perhaps even beyond—the human one.
Admittedly, diffusion language models do not construct a brand-new language; they still learn from human text, and what they ultimately produce is still human writing arranged in a line. But remember: the letter Louise writes to her daughter is still line after line of left-to-right English—yet the consciousness that wrote it has been utterly transformed. For a model, its “cognition” resides precisely in the process of computation: once generation is no longer constrained by the causal mask, the way the model views a passage of text—which parts are settled first, which parts determine one another—is already fundamentally different from that of an autoregressive model.
Even setting aside the metaphysical hypothesis that diffusion language models are closer to superintelligence, today’s diffusion language models have already demonstrated practical value and application potential that cannot be ignored:
- A higher learning ceiling when data is limited: the paper Diffusion Language Models are Super Data Learners[2] reveals that when training data has to be repeated, diffusion language models are harder to overfit than autoregressive ones and possess a higher ceiling of learning capacity. Model sizes keep scaling up; if the growth of data slows or stalls, diffusion language models may be able to reach higher levels of intelligence through repeated learning.
- Faster inference for local deployment: when a model is deployed and run locally, there is usually only one inference request at a time (so-called batch-1 inference). An autoregressive language model generates only one token per forward pass; in this setting the chip’s compute units are poorly utilized, and inference latency is bounded mainly by memory bandwidth. A diffusion language model generates multiple tokens per forward pass, improving compute utilization and achieving faster inference. According to the official DiffusionGemma blog[3], with the same chip and model size, a diffusion language model runs four times faster than an autoregressive one on batch-1 inference.
- A unified continuous modeling paradigm for multimodality: when an autoregressive language model wants to incorporate other modalities (vision, audio, and so on), it must discretize their representations in order to fit the next-token-prediction paradigm—a modeling step that inevitably loses information. As continuous diffusion language models mature, diffusion offers a unified modeling paradigm over continuous representations for language, vision, and audio alike; the techniques diffusion models have developed for image, audio, and video generation also have room to generalize, opening the door to faster, higher-quality multimodal generation.
Foreseeing the future has always been humanity’s image of ultimate wisdom. Diffusion language models, from the angle of how the form of expression shapes consciousness, offer another possible way of perceiving the world. Perhaps, within a nutshell of electrical signals, there really could grow a superintelligence that walks freely in every direction of time, exploring an infinite universe.
Comments